

Ny teknik ska hjälpa digitala verktyg förstå homonymer
Digitalisering
Ord med flera betydelser är en utmaning för datorer. Damm, fil, banan, fasan är homografer som om de används i en chat eller vid översättning – kan få förvirrade svar. Nu kommer en avhandling som visar att det är möjligt att lära sig ordens olika innebörd.

I dag är chat en stor kommunikationskanal och något som växer. Yngre personer väljer hellre en snabb chatt än mankemanget att behöva ringa upp. I takt med digitaliseringen, där automatisering av chat och digitala assistenter är en viktig del, kan det dock bli problem för datorerna att hänga med. För hur ska en ai veta om det är musikgenren eller ett plagg som avses när personer använder ordet rock.
Luis Nieto Pinã har skrivit en avhandling där han visar att det är möjligt att lära datorer skillnaderna.
Nuvarande semantiska modeller, som använder sig av en större kvantitet av text för inlärning, tenderar att ge ord enbart en betydelse. På så vis sammanfogas de olika innebörderna som ett ord kan ha till en enda.
– min avhandling visar jag dels att det är möjligt att anpassa sådana semantiska modeller till att lära sig flera betydelser av ett enda ord, och även att dessa modeller förbättras när de data som används för inlärning av ordbetydelse inte enbart består av text utan även av språkresurser som lexikon, säger Luis Nieto Piña, doktorand vid Göteborgs universitet.
Semantiska modeller som informerar datorn om ords betydelser är avgörande i de flesta system som hanterar språk: automatisk översättning av text, nyhetssammanfattningar, sentimentanalys av kundrecensioner, chatbots som ger kundservice och så vidare.
– Avhandlingen erbjuder förbättrade sätt för sådana system att förstå ordbetydelser. Det kan förbättra systemens prestanda och därmed användarupplevelsen.
Och alla som försökt översätta en text genom Google Translate vet hur fel det kan bli.
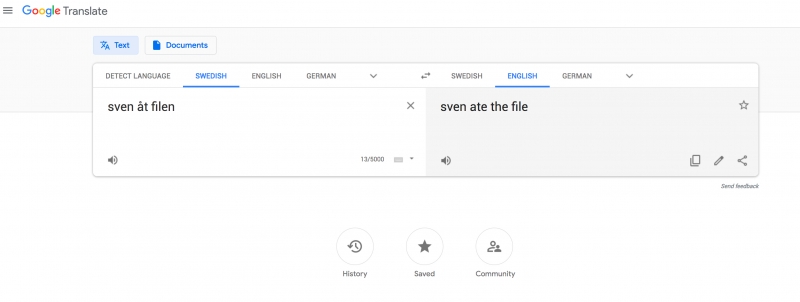
– Vanligt förekommande automatiska översättningsfel som ”Sven åt filen” översatt till den engelska meningen som ”Sven ate the file” skulle kunna undvikas genom att använda modeller som presenteras i avhandlingen. Dessutom kan dessa nya modeller ge en möjlighet att använda moderna maskininlärningstekniker för att bearbeta lexikon. I praktiken innebär det att forskare som ansvarar för att utveckla lexikon kan automatisera vissa uppgifter och minska sitt manuella arbete.
Syftet med avhandlingen har varit att försöka erbjuda bättre modeller för ordbetydelse och att dessa ska göra att applikationer som arbetar med språk blir bättre.
Här går det att läsa hela avhandlingen: Splitting rocks: Learning word sense representations from corpora and lexica.


